
● WINDOW FUNCTION
- 서로 다른 행의 비교나 연산을 위해 만든 함수
- GROUP BY 를 쓰지 않고 그룹 연산 가능
- LAG, LEAD, SUM, AVG, MIN, MAX, COUNT, RANK
** 문법

** PARTITION BY 절 : 출력할 총 데이터 수 변화 없이 그룹연산 수행할 GROUP BY 컬럼
** ORDER BY 절
- RANK 의 경우 필수(정렬 컬럼 및 정렬 순서에 따라 순위 변화)
- SUM, AVG, MIN, MAX, COUNT 등은 누적값 출력 시 사용
** ROWS|RANGE BETWEEN A AND B
- 연산 범위 설정
- ORDER BY 절 필수
※ PARTITON BY, ORDER BY, ROWS... 절 전달 순서 중요(ORDER BY 를 PARTITON BY 전에 사용 불가)
예제) 그룹함수 오류(윈도우 함수가 필요한 이유)

☞ 전체를 출력하는 컬럼과 그룹함수 결과는 함께 출력할 수 없음
● 그룹 함수의 형태
- SUM, COUNT, AVG, MIN, MAX 등
- OVER 절을 사용하여 윈도우 함수로 사용 가능
- 반드시 연산할 대상을 그룹함수의 입력값으로 전달
** 문법

1) SUM OVER()
- 전체 총 합, 그룹별 총 합 출력 가능
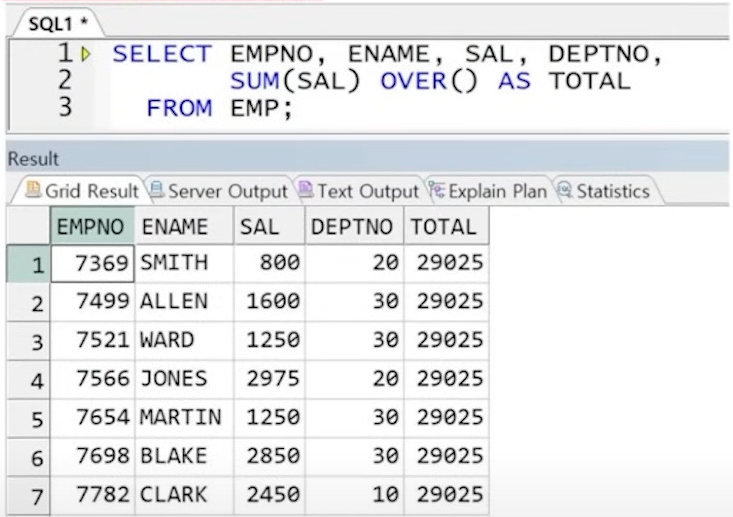
예) 각 직원 정보와 함께 급여 총 합 출력
** 에러 : 각 직원 정보와 급여 총 합(그룹함수 결과)를 동시에 출력 시도 시 에러 발생

** 해결 1 : 서브쿼리 사용(스칼라 서브쿼리)

** 해결 2 : 윈도우 함수 사용
2. AVG OVER() : SUM과 동일하게 사용
예제) 각 직원 정보와 해당 직원이 속한 부서의 평균 급여 출력

3. MIM/MAX OVER() : SUM 과 동일하게 사용
예제) 각 직원 정보와 해당 직원이 속한 부서의 최대급여를 함께 출력

4. COUNT : SUM 과 동일하게 사용
** 윈도우 함수의 연산 범위 : 집계 연산 시 행위 범위 설정 가능
1. ROWS, RANGE 차이
1) ROWS : 값이 같더라도 각 행씩 연산
2) RANGE : 같은 값의 경우 하나의 RANGE 로 묶어서 동시 연산(DEFAULT)
2. BETWEEN A AND B
A) 시작점 정의
- CURRENT ROW : 현재행부터
- UNBOUNDED PRECEDING : 처음부터(DEFAULT)
- N PRECEDING : N 이전부터
B) 마지막 시점 정의
- CURRENT ROW : 현재행까지(DEFAULT)
- UNBOUNDED FOLLOWING : 마지막까지
- N FOLLOWING : N 이후까지
예제) RANGE_TEST 테이블에서의 범위 설정에 따른 누적합
** CASE1)RANGE 범위 전달(DEFAULT) : 값이 같을 경우 같은 범위로 취급하여 동시 연산

** CASE2)ROWS 범위 설정 시 : 각 행 별로 연산 수행

** CASE3)BETWEEN A AND B 수정 시

☞ UNBOUNDED PRECEDING AND 1 FOLLOWING : 각 행마다 누적합 계산 시 처음부터 다음행까지 연산
● 순위 관련 함수
1) RANK(순위)
1-1) RANK WITHIN GROUP
- 특정값에 대한 순위 확인(RANK WITHIN)
- 윈도우함수가 아닌 일반함수
** 문법

예) EMP 에서 급여가 3000이면 전체 급여 순위가 얼마?

2-2) RANK()OVER()
- 전체 중/특정 그룹 중 값의 순위 확인
- ORDER BY 절 필수
- 순위를 구할 대상을 ORDER BY 절에 명시(여러 개 나열 가능)
- 그룹 내 순위 구할 시 PARTITION BY 절 사용
** 문법

예) 각 직원의 급여의 전체 순위(큰 순서대로)

예) 각 직원 이름, 부서번호, 급여, 부서별 급여 순위(큰 순서대로)

3) DENSE_RANK
- 누적순위
- 값이 같을 때 동일한 순위 부여 후 다음 순위가 바로 이어지는 순위 부여 방식
ex) 1 등이 5 명이더라도 그 다음 순위가 2 등
4) ROW_NUMBER
- 연속된 행 번호
- 동일한 순위를 인정하지 않고 단순히 순서대로 나열한대로의 순서 값 리턴
예제) RANK, DENSE_RANK, ROW_NUMBER 비교

● LAG, LEAD
- 행 순서대로 각각 이전 값(LAG), 이후 값(LEAD) 가져오기
- ORDER BY 절 필수
** 문법

예) EMP 에서 바로 이전 입사자와 급여 비교

참고) 이전/이후 값 가져올 때 이전 값이 같더라도 항상 행의 순서대로 이전,이후 하나를 가져옴
따라서 사용자가 이전/이후 값을 가져올 원하는 행 배치를 ORDER BY 를 통해 충분히 전달 한 후
이전/이후 값을 가져오면 됨

● FIRST_VALUE, LAST_VALUE
- 정렬 순서대로 정해진 범위에서의 처음 값, 마지막 값 출력
- 순서와 범위 정의에 따라 최소값과 최댓값 리턴 가능
- PARTITION BY , ORDER BY 절 생략 가능
** 문법

예제) FIREST_VALUE 를 사용한 최소, 최대 출력

예제) LAST_VALUE 를 사용한 최소, 최대 출력

● NTILE
- 행을 특정 컬럼 순서에 따라 정해진 수의 그룹으로 나누기 위한 함수
- 그룹 번호가 리턴됨
- ORDER BY 필수
- PARTITION BY 를 사용하여 특정 그룹을 또 원하는 수 만큼 그룹 분리 가능
- 총 행의 수가 명확히 나눠지지 않을 때 앞 그룹의 크기가 더 크게 분리됨
ex) 14명 3개 그룹 분리 시 -> 5, 5, 4 로 나뉨
** 문법

예제) NTILE 을 사용한 그룹 분리

● 비율관련 함수
1) RATIO_TO_REPORT
- 각 값의 비율 리턴(전체 비율 또는 특정 그룹 내 비율 가능)
- ORDER BY 사용 불가
** 문법

2) CUME_DIST : 각 행의 수에 대한 누적비율
- 특정 값이 전체 데이터 집합에서 차지하는 위치를 백분위수로 계산하여 출력
- ORDER BY 를 사용하여 누적비율을 구하는 순서 정할 수 있음
- ORDER BY 필수
- 값이 3 개이면 1/3 = 0.33 부터 시작
** 문법

3) PERCENT_RANK
- PERCENTILE(분위수) 출력
- 전체 COUNT 중 상대적 위치 출력(0~1 범위 내)
- ORDER BY 필수
** 문법

예제) CUME_DIST 와 PERCENT_RANK 비교

예제) 누적 비율 비교
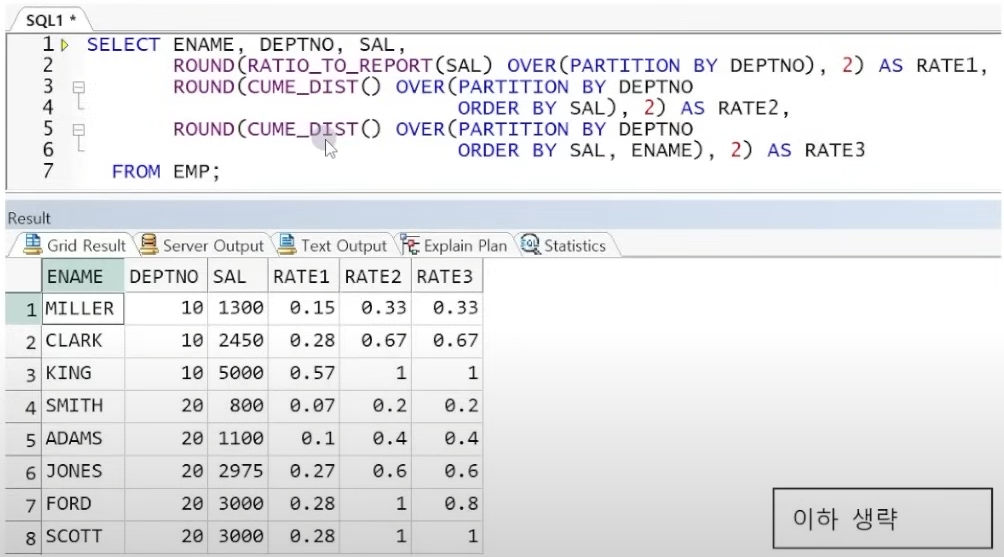
☞ RATE2 : SAL 에 대해서만 순서 정렬 후 RANGE 로 누적비율을 구하므로 FORD 와 SCOTT 의 급여 누적 비율이 같아짐(SAL 값이 같으니까 하나의 범위로 처리)
☞ RATE3 : ORDER BY 로 SAL, ENAME 의 순서를 정의하므로 두 값이 모두 같을 때만 RANGE 처리 하게 됨
=> FORD 와 SCOTT 이 SAL 값이 같더라도 ENAME 값에 의해 두 행의 범위가 달라지므로 각각 연산됨
☞ CUME_DIST 는 RATIO_TO_REPORT 처럼 비율을 계산할 값을 지정하지 않는다. 따라서 특정 값이 아닌, 각 행이 전체 혹은 PARTITION 내에 차지하고 있는 비율을 의미함(MILLER 는 10 번 부서원 총 3명 중 1명의 비율을 의미함)
예제) PERCENT_RANK 예제
