
● 식별자 구분(대체 여부에 따른)
1) 본질식별자
- 업무에 의해 만들어지는 식별자(꼭 필요한 식별자)
2) 인조식별자
- 인위적으로 만들어지는 식별자(꼭 필요하지 않지만 관리의 편의성 등의 이유로 인위적으로 만들어지는 식별자)
- 본질식별자가 복잡한 구성을 가질때 인위적으로 생성
- 주로 각 행을 구분하기 위한 기본키로 사용되며 자동으로 증가하는 일련번호 같은 형태임
예제) 주문과 주문상세에 대한 엔터티 설계 과정을 예를 들어보자.
주문이 들어오면 주문 엔터티에는 (주문번호 + 고객번호)를 저장, 이 때 PK는 주문번호이다.
주문상세에는 각 주문별로 어떤 상품이, 언제, 몇 개 주문됐는지 등을 기록한다.

※ 주문상세 테이블 설계 시 다음과 같은 식별자를 고려할 수 있다.
1.PK : 주문번호 + 상품번호로 설계
- 주문을 하면 주문번호와 성품번호가 필요하므로 본질식별자(주문번호 + 상품번호)가 된다
- 하지만 PK 가 주문번호 + 상품번호이면 하나의 주문번호로 같은 상품의 주문 결과를 저장할 수 없게 된다.

☞ 실제로 쇼핑을 하다보면 동일한 장바구니에 A 상품을 5개 주문했는데, 뒤에 또 다시 A 상품을 3개 추가로
주문하기도 함
2. PK : 주문번호 + 주문순번(주문순번이라는 컬럼을 생성)
- 하나의 주문에 여러 상품에 대한 주문 결과 저장 가능 -> 주문순번으로 인해 구분함
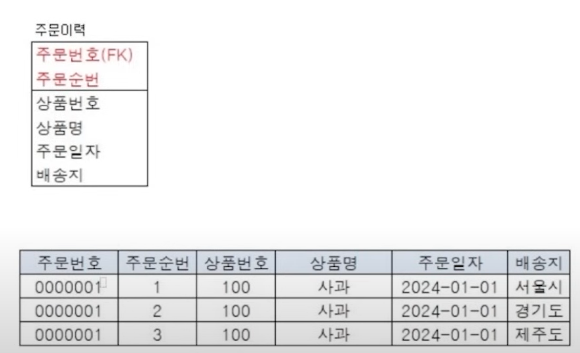
☞ 매 주문마다 동일한 상품 주문 시 주문순번을 정하기 위해 상품의 주문 횟수를 세야한다는 점이 매우 불편!
즉, 사과를 총 3번 구매 하였으니 주문순번은 1,2,3 순서대로 입력돼야 함
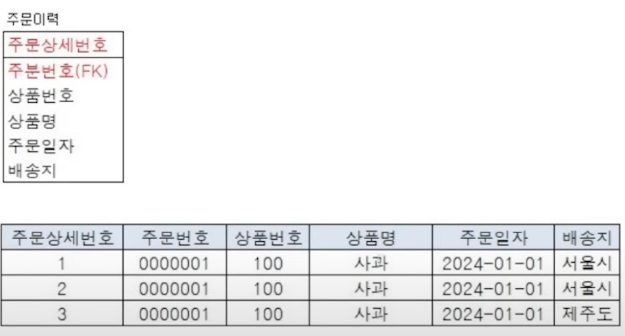
3. PK : 주문상세번호(인조식별자 생성)
- 주문상세번호로 각 주문이력을 구분하기 때문에 같은 주문의 같은 상품이력이 저장될 수 있음
- 주문상세번호만이 주식별자이므로 나머지 정보들이 불필요하게 중복 저장될 위험 발생
- 실제 업무와 상관없는 주문상세번호를 주식별자로 생성하면 쓸모없는 index 가 생성됨(PK 생성 시
자동 unique index 생성)
※ 따라서 인조식별자는 다음의 단점을 가지게 된다.
1. 중복 데이터 발생 가능성 -> 데이터 품질 저하
2. 불필요한 인덱스 생성 -> 저장공간 낭비 및 DML 성능 저하
** 인덱스는 원래 조회 성능을 향상시키기 위한 객체이며, 인덱스는 DML(INSERT/UPDATE/DELETE)시
INDEX SPLIT 현상으로 인해 성능이 저하된다.